




診察室に入ってきた患者(患者でなくても診察室に入ったら患者になる)の顔も見ずに、医師はさっさと患者の腕に血圧計のマンシェットを巻き、送気球をシュッシュッと押しはじめる。スーッと空気を抜いたところで残念そうな表情で「うーん、ちょっと高目ですね」と。
血圧には基準値がある。正常値とも呼ばれる130/85という数字を超えると、異常と診断される。正常値から逸脱しているから、異常だ。この正常値の中身をみると、いわゆる平均基準であることに気付く。現代人は基準値という怪物に結構騙されている。つまり、統計上の正規分布である。
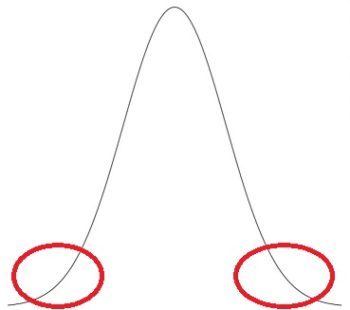
データを取るには調査が必要。調査対象人数を増やしていくと、平均値付近のデータ数がもっとも多く、両端のデータ数が少ない、という左右対称のつりがね型の分布になる。このつりがね型の分布を「正規分布」という。そこからいわゆる「正常値」が出される。
では、少数データの両端はすべて異常だろうか。血圧でいえば、患者の年齢や性別、身長、体重、職業、家族(遺伝等)、生活・健康状況、計測前の運動・静止状態、食事内容などといった要素を折り込んでいくと様子が違ってくるかもしれない。これらの要素を一切排除してたった1つの基準値(正常値)に照らして結論付けていいのだろうか。
偏差値という概念には、日本人が過剰な親近感を持っている。大学や学部まで偏差値をつけられ、統計学が人生の最初から最後まで付きまとう。今の世界は、何でもデータでないと信用されない。だが、データはまさに魔法がかかっているもので、人間は騙されやすいのだ。
私がビジネススクールで学んだスキルの1つは、データの取り方と使い方。たとえばサーベイ(調査)でも設問の仕方によって回答が異なってきたりする(データの取り方)。さらに主張したい結論を裏付けるためのデータを寄せ集め、反証となるデータを隠蔽したりすることもそう難しくない(データの使い方)。
データを信用するなと言っているわけではない。データの取り方、使い方、そしてデータを使う当事者の利害関係をまず読むことが大事だと言っている。そして自分からデータをとって分析することだ。